
Snowflake Architecture

What is snowflake Architecture? Why Snowflake?
You’re looking for a game-changing tool to make your IT infrastructure stronger than ever. Perhaps you’re already in the cloud with one of the leading cloud providers (AWS, Microsoft Azure, or Google Cloud Platform), but there are some aspects you believe could be improved, and thus you’re ready for a big change. Perhaps you simply want to learn more about Snowflake because you’ve heard so many good things about it.
We will also do a free hands-on practice to show you how to get started with Snowflake! But first, let’s talk about the Snowflake architecture and how it differs from other data platforms you’ve seen.
Snowflake Architecture Concepts 2023
Snowflake architecture combines the advantages of shared-disk and shared-nothing structures. Traditional shared-disk and shared-nothing database architectures are combined to create the Snowflake architecture. As with shared-disk architectures, all compute nodes in the Snowflake platform have access to a single central data repository for persisted data. Snowflake, however, processes queries using MPP (massively parallel processing) compute clusters, where each node in the cluster stores a portion of the entire data set locally, similar to shared-nothing architectures. With this strategy, you get the performance and scale-out advantages of a shared-nothing architecture along with the shared-disk architecture’s ease of data management.
Let’s take a look at each of these designs and see how Snowflake combines them to form a new hybrid architecture:
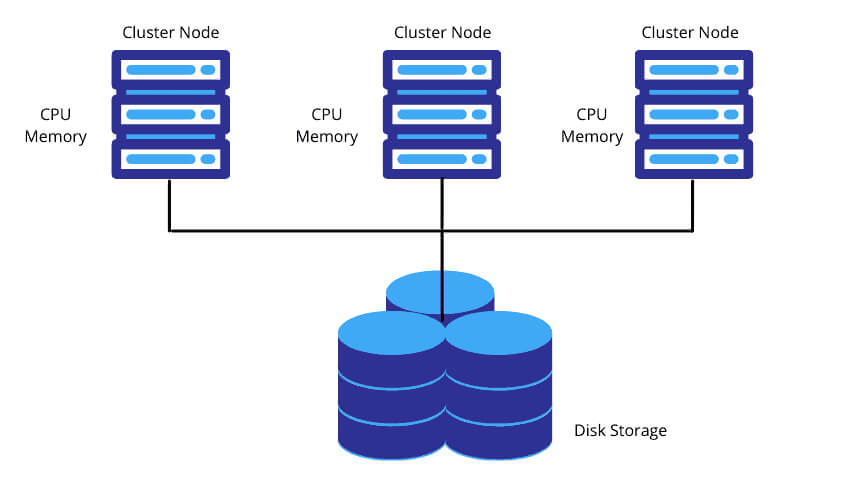
Shared-disk architecture: This type of architecture is commonly used in traditional databases and consists of a single storage layer that is accessible to all grade levels. To retrieve and interpret data, multiple cluster nodes equipped with CPU and memory communicate with the centralized storage layer.
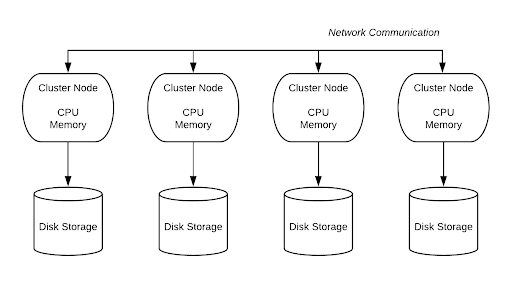
Shared-nothing architecture: In contrast to the Shared-Disk design, it employs dispersed cluster nodes, each with its own disc storage, CPU, and memory. The advantage is that data can be divided and saved among cluster nodes because each has its own storage space.
Types of Snowflake Data Warehouse Architecture
There are primarily 3 methods for creating a data warehouse:
Single-tier Architecture: To reduce the amount of data stored, this type of architecture works to duplicate data.
Two-tier architecture: This design separates the Data Warehouse from the physical Data Sources. As a result, the Data Warehouse is unable to grow and support numerous end users.
Three-tier architecture: This design consists of three tiers. The Data Warehouse Servers’ Databases make up the bottom tier, followed by an OLAP Server in the middle that offers an abstracted view of the Database and, finally, a Front-end Client Layer at the top that includes the tools and APIs required for data extraction.






Components of Snowflake Data Warehouse Architecture
A data warehouse consists of the four items listed below.
Data Warehouse and Database
A Data Warehouse requires a database as a key component. Data about the business is stored and accessible in a database. Cloud-based Database services include Azure SQL and Amazon Redshift.
Extracting, Modifying, and Loading Tools (ETL)
This component encompasses all activities involved in the Extraction, Transformation, and Loading (ETL) of data into the warehouse. Traditional ETL tools are used to gather data from various sources, format it for consumption, and then load it into a data warehouse.
Metadata
Data construction, storage, handling, and use are made possible by the framework and descriptions that metadata provides.
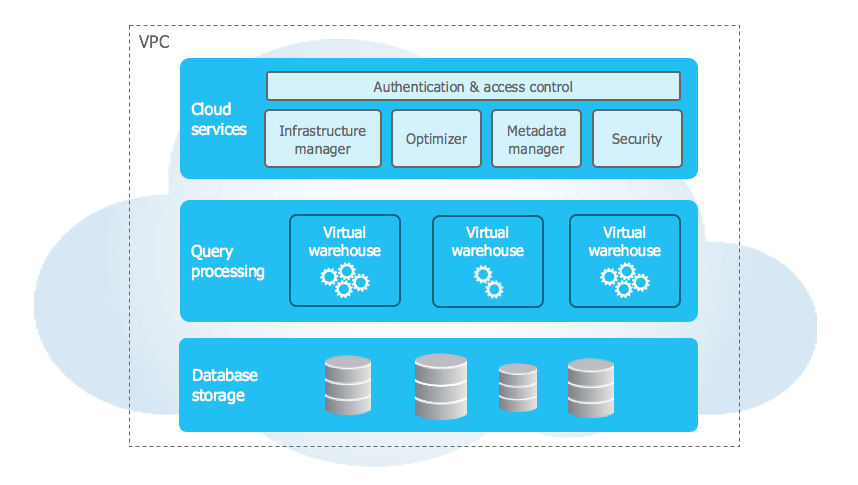
Cloud Architecture Layers
The diagram below shows the high-level architecture that Snowflake supports. Each snowflake has three layers:
- Storage Layer
- Cloud Services Layer
- Computing Layer
Storage Layer
The data is divided up into a number of internal optimized and compressed micro partitions by Snowflake. It stores information in a columnar format. Data management is made simple by using cloud storage, which operates as a shared-disk model. In the shared-nothing model, this ensures that users do not have to be concerned about data distribution across numerous nodes.
To obtain the data needed for query processing, compute nodes connect with the storage layer. We only pay for the typical monthly storage used because the storage layer is independent. Since Snowflake is cloud-based, storage is elastic and billed monthly based on usage measured in TB.
Computer Layer
Snowflake runs queries using the “Virtual Warehouse” (described below). The query processing layer is divided from the disc storage by snowflake. Utilizing the data from the storage layer, queries run in this layer.
Virtual Warehouses are MPP compute clusters with numerous nodes and Snowflake-provisioned CPU and Memory that are made up of virtual warehouses. Depending on workloads, Snowflake can create a variety of Virtual Warehouses to meet different requirements. One storage layer is capable of supporting each virtual warehouse. The majority of the time, a virtual warehouse operates independently and does not communicate with other virtual warehouses.
Virtual Warehouse Benefits
Here are a few benefits of virtual warehouses:
- Virtual Warehouses can be started, stopped, and scaled at any time without affecting currently running queries.
- They can also be set to automatically suspend or resume warehouses so that they are suspended after a predetermined amount of inactivity and resumed when a query is sent.
- They can also be configured to automatically scale with minimum and maximum cluster sizes; for example, we could set minimum to 1 and maximum to 3, allowing Snowflake to provision anywhere from 1 to 3 multi-cluster warehouses depending on the load.
Layer of Cloud Services
This layer is where all coordinated Snowflake-wide operations like authentication, security, metadata management of the loaded data, and query optimization take place.
Services handled by this layer include, for example:
- This layer must be traversed in order to process login requests. Snowflake queries are sent to this layer’s optimizer and then sent to the compute layer for processing.
- This layer stores the metadata needed to filter or optimize a query.
These three layers’ scale independently of one another, and Snowflake assesses separate fees for virtual warehouse and storage.
Top 12 Snowflake Features 2023
Snowflake’s Cloud Data Platform is a popular choice among businesses looking to modernize their data architecture. What differs it from other cloud data warehouse solutions like Amazon Redshift or Azure Synapse? This article discusses 12 unique and noteworthy features of Snowflake that set it apart.
1. Snowflake’s decoupling of computation and storage
Virtual warehouses and storage as distinct entities are made possible by Snowflake’s decoupling of storage and compute features. By utilizing this Snowflake functionality, businesses can increase their flexibility in selecting the compute of their choice and pay incrementally for what they store and compute. According to the business’s SLA requirements, users can scale up, down, or in or out. Scale up – Scale-out features operate almost instantly and without downtime.
2. Automatic Resume, Suspend, and Scale
Minimal administration is provided by Snowflake’s auto-resume and auto-suspend features. Snowflake starts a compute cluster using auto-resume when a query is triggered and suspends compute clusters after a predetermined amount of inactivity. Performance optimization, cost control, and flexibility are all made possible by these two features.
Setting up auto-scaling can help expand the number of clusters from 1 to 10 at an increment of 1, depending on the volume of queries sent to a compute simultaneously, in business situations where more users are querying heterogeneous queries.
3. Workload Concurrency and Separation
Unlike traditional data warehouses with concurrency issues, where users and processes must compete for resources, concurrency is no longer a problem for Snowflake. Concurrency is no longer a problem thanks to Snowflake’s multi-cluster architecture.
This architecture also aids in the division of workloads into their respective virtual warehouses and the routing of traffic by departments or functions to each virtual compute warehouse.
4. Snowflake Management
Snowflake offers a data cloud as a service (DWaas). Businesses don’t need much help from DBA or IT teams to set up and manage a system. Hardware commissioning and software installation patch-update are not required, in contrast to on premise platforms. Without any downtime, Snowflake manages software updates and adds new features and patches.
Micro-partitioning is automatically created by Snowflake. Despite the fact that Snowflake has features for manually clustering and indexing tables, this feature reduces the need for that.
5. Agnostic cloud
Snowflake’s platform is cloud-agnostic, allowing it to migrate its workloads to other cloud service providers. AWS, Azure, and GCP are the three cloud service providers where Snowflake is available. Customers can deploy Snowflake in locations that are preferred by their companies and integrate it easily into their current cloud architecture.
6. Storage of Semi-Structured Data
NoSQL database solutions were developed to handle semi-structured data, which is frequently in JSON format. To extract attributes from JSON and combine them with structured data, data pipelines are developed.
Snowflake’s design enables storing structured and semi-structured data in the precise location by utilizing VARIANT, a schema on read data type. The VARIANT data type can be used to store structured and semi-structured data. Snowflake automatically analyses data, extracts properties, and saves it in a columnar format, eliminating the need for data extraction pipelines.
For the purpose of retrieving and transforming files kept on these platforms, Snowflake can connect to staging areas like S3 buckets, Azure blobs, or GCP blob storage. No matter which cloud Snowflake is hosted on, this is true. There is also a staging area that is managed by snowflakes. Data can be retrieved at a predetermined time or almost instantly using Tasks/Streams, Snow pipe, or both. The file formats Avro, ORC, Parquet, JSON, XML, and CSV are all compatible with Snowflake. The unstructured data kept in the staging area can also have its metadata stored in Snowflake.
7. Data Exchange
The Marketplace offers a huge selection of data, data services, and applications. Through Marketplace, you can find, evaluate, and buy data, data services, and apps from some of the top data and solution suppliers in the world. The costs and delays involved with traditional ETL operations and integration are essentially eliminated by direct access to data that is ready for querying and pre-built SaaS connections. It is best to avoid copying and moving out-of-date content due to the risk and hassle involved. Instead, you can have secure access to shared, managed, and live data and get automatic updates that are nearly real-time.
8. Time Travel
Time travel is one of the distinctive features of Snowflake. Time travel allows you to track the development of data over time. This Snowflake feature is available to all accounts, is cost-free, and is turned on by default for everyone. You can also access the previous data from a Table using this Snowflake feature. Access to the table’s appearance over the previous 90 days is possible at any time.
The undrop feature encompasses time travel. Using the undrop command in Snowflake, a dropped object can be recovered if the system has not yet removed it. An object that has been dropped returns to its initial state when it is undropped. Additionally, there is the choice to restore dropped tables or schemas.
9. Cloning
We can quickly replicate anything using the clone feature, including databases, schemas, tables, and other Snowflake objects, in nearly real time. As a result, altering an object’s metadata rather than its storage contents constitutes cloning. For testing purposes, you can quickly create a copy of the entire production database.
10. Snow Park
Data scientists and data engineers skilled in Python, Scala, R, and Java can create and manage their codes in Snowflake with the aid of the Snowpark feature. In order to retrieve, transform, train, and apply data science models on the data stored in Snowflake, which has a more pronounced performance advantage, Snowpark assists in using the computing capabilities of Snowflake.
11. Snowsight
The new Snowflake web user interface, Snowsight, replaces the conventional Snowflake SQL Worksheet and enables you to easily create basic charts and dashboards that can be shared or explored by many users, perform data validation while loading data, and perform ad-hoc data analysis. The Snowflake dashboards tool is a great choice because it works well for individuals or small groups of users in an organization who want to create simple visualizations and share information among themselves.
Security Features
The following techniques are used by Snowflake to guarantee user security:
Supporting multiple authentication methods, such as federated authentication and two-factor authentication for SSO. By adding IP addresses to a whitelist, you can manage network policies and restrict who can access your account.
Adopting a hybrid strategy that combines role-based access control with discretionary access control. In role-based access control, roles are given privileges, which are then given to users. The owner of each object in the account still has control over access to the object in discretionary access control. A high degree of flexibility and control are provided by this hybrid strategy.
All data is automatically encrypted both in transit and at rest using the powerful AES 256 encryption.
How to Figure Out SnowSQL
SnowSQL for bulk loading
Staging files is done in phase 1 of bulk data loading, and loading data is done in phase 2 of bulk data loading. Here, our main emphasis will be on loading data from CSV files.
In the demo database demo db, we’ll see a SnowSQL SQL client loading CSV files from a local computer into a table called Contacts. The name will be used to store the files before loading in the internal staging.
Use demo_db database
Last login : Sat Sep 19 14:20:05 on ttys011
Superuser-MacBook-Pro: Documents xyzdata$ snowsql -a bulk_data_load
User: peter
Password:
* SnowSQL * V1.1.65
Type SQL statements or !help
* SnowSQL * V1.1.65
Type SQL statements or !help
johndoe#(no warehouse)@(no database).(no schema)>USE DATABASE demo_db;
+-------------------------------------------------------------------------------+) produced. Time Elapsed: 2.111s
| status |
+-------------------------------------------------------------------------------+
| Statement executed successfully. |
+-------------------------------------------------------------------------------+
1 Row(s) produced. Time Elapsed: 0.219s
The table were created
peter#(no warehouse)@(DEMO_DB.PUBLIC)>CREATE OR REPLACE TABLEcontacts
(
id NUMBER (38, 0)
first_name STRING,
last_name STRING,
company STRING,
email STRING,
workphone STRING,
cellphone STRING,
streetaddress STRING,
city STRING,
postalcode NUMBER (38, 0)
)
+-------------------------------------------------------------------------------+
| status |
+-------------------------------------------------------------------------------+
| Statement executed successfully. |
+-------------------------------------------------------------------------------+
1 Row(s) produced. Time Elapsed: 0.219s
Next to create an internal stage called csvfiles.
peter#(no warehouse)@(DEMO_DB.PUBLIC)>CREATESTAGE csvfiles;
+-------------------------------------------------------------------------------+
| status |
+-------------------------------------------------------------------------------+
| Stage area CSVFILES successfully created. |
+-------------------------------------------------------------------------------+
1 Row(s) produced. Time Elapsed: 0.311s
PUT command is used to stage the records in csvfiles. This command uses the wildcard contacts0*.csv to load multiple files, and the @ symbol specifies where to stage the files, in this case, @csvfiles.
peter#(no warehouse)@(DEMO_DB.PUBLIC)>PUT file:///tmp/load/contacts0*.csv @csvfiles;
contacts01.csv_c.gz(0.00MB): [##########] 100.00% Done (0.417s, 0.00MB/s),
contacts02.csv_c.gz(0.00MB): [##########] 100.00% Done (0.377s, 0.00MB/s),
contacts03.csv_c.gz(0.00MB): [##########] 100.00% Done (0.391s, 0.00MB/s),
contacts04.csv_c.gz(0.00MB): [##########] 100.00% Done (0.396s, 0.00MB/s),
contacts05.csv_c.gz(0.00MB): [##########] 100.00% Done (0.399s, 0.00MB/s),
+----------------+-------------------+-------------+------------------- -------------+
| source | target | source_size | target_size | status |
| contacts01.csv | contacts01.csv.gz | 554 | 412 | UPLOADED |
| contacts02.csv | contacts02.csv.gz | 524 | 400 | UPLOADED |
| contacts03.csv | contacts03.csv.gz | 491 | 399 | UPLOADED |
| contacts04.csv | contacts04.csv.gz | 481 | 388 | UPLOADED |
| contacts05.csv | contacts05.csv.gz | 489 | 376 | UPLOADED |
+------------------------------------------------- ---+
| Stage area CSVFILES successfully created. |
+--------------------------------------------------------------------------------------+
5 Row(s) produced. Time Elapsed: 2.111s
To confirm cvsfile have used the LIST command
peter#(no warehouse)@(DEMO_DB.PUBLIC)>LIST @csvfiles;
LOAD the file from stage files into the CONTACTS table
peter#(no warehouse)@(DEMO_DB.PUBLIC)>USE WAREHOUSE dataload;
+-------------------------------------------------------------------------------+
| status |
+-------------------------------------------------------------------------------+
| Statement executed successfully. |
+-------------------------------------------------------------------------------+
1 Row(s) produced. Time Elapsed: 0.203s
Load the stage file into Snowflake table
peter#(DATALOAD)@(DEMO_DB.PUBLIC)>COPY INTO contacts; FROM @csvfiles PATTERN = '.*contacts0[1-4].csv.gz' ON_ERROR = 'skip_file';
INTO define where the table data to be loaded. PATTERN specified the data file, ON_ERROR command when its encounter the errors.
If the load was successful, now you can query the table using SQL
peter#(DATALOAD)@(DEMO_DB.PUBLIC)>SELECT * FROM contacts LIMIT 10;
Conclusion
In order to improve your data warehouse use cases and make them easier to create and maintain, consider using a user-friendly platform like Snowflake. This blog was written with the intention of giving you a deeper understanding of snowflake architecture.



