

What is Selenium Web Driver?
In the world of automated software testing, Selenium WebDriver is a crucial tool. It is an open-source framework that gives users a powerful API to interact with web applications through web browsers. With the help of Selenium WebDriver, developers and testers can automate common browser tasks like clicking buttons, completing forms, and browsing around websites. It is flexible for writing test scripts because it supports a wide range of programming languages. Selenium WebDriver is essential for ensuring that web applications work and are compatible across various platforms and browsers, which helps to ensure the effectiveness and dependability of software testing procedures.
Let us learn more about the Selenium architecture by referring to this BTree Selenium with Python Course in Chennai.
Another one of its popular uses is as a web scraping tool, with which it is possible to scrape websites, pull out their raw data and store it in an easily accessible format. For example, in order to find the right candidate for a role instead of doing interviews, it is possible to simply scrape a job website and scrape the users who fit the role the most and then call them for an interview. All of this takes less than 10 minutes to perform.
Selenium also has several components in it which converge into a tool called the Selenium Suite. It is made up of several components which will be seen more in the next section.
Understanding Tools in Selenium Suite
There are several tools in the Selenium Suite. They are
- Integrated Development Environment (IDE)
- WebDriver
- Selenium Remote Control
- Selenium Grid
Let us understand each one of the tools in detail in this section.
Integrated Development Environment (IDE)
Selenium provides its own IDE with which it is possible to test browser automation techniques or prototypes and build codes with relative ease. It was originally developed as a Firefox plugin. It is used by web developers to create a variety of test cases quickly, and efficiently.
WebDriver
Also known as Selenium 2 is a feature added to Selenium, in which instead of using APIs (Application Programming Interface) to automate browsers with code, it uses the native support of different browsers available to perform Browser testing/automation. There are different types of WebDrivers provided by different browsers.
It is not possible to perform web automation without the browser’s native support in its HTML codes to manipulate it to get the required output. Hence, the WebDriver is the most integral part of Selenium.
Selenium RC (Remote Control)
It is also known as Selenium 1. It was the first tool out of the Selenium suite which was sent out to perform Web Automation. It provided a programmable API with which developers could write programs performing Web Automation.
It returns a JavaScript code when loaded with a test script, similar to the requests module in Python. It uses these JavaScript code elements to interact with different browsers available. This is currently deprecated and is defunct with WebDriver architecture slowly phasing out Selenium RC.
Selenium Grid
This operation is used to run web automation tests parallely in multiple browsers. When there are thousands of test cases, it is impossible to test them manually for every single browser. When the code is very huge, it makes it difficult to detect any bugs. With Grid, which is usually clubbed with Selenium RC, you can run the code parallelly in different browsers to detect and pinpoint bugs.
Now that we’ve seen all the tools of the Selenium Suite, let us dive deeper into understanding how the Selenium IDE works and its functionalities in detail.
Understanding the Selenium IDE
The Selenium IDE (Integrated Development Environment) is an IDE provided by Selenium. It is available to test for the browsers Google Chrome and Mozilla Firefox.
It is used in order to develop different test cases and run them with the browsers to check their applicability. It is an excellent no-code environment, which implies that little to no coding knowledge is required to work in Selenium IDE as opposed to other elements of the Selenium suite. Since it has little coding knowledge requirements, it is easy to Debug if there are any bugs spotted.
For easier use-case applications, the IDE follows a control flow structure with which we can deploy snippets of code using the if, else and times functions. It is also available as an extension in Google Chrome. The functionalities of the IDE can also be expanded upon with the introduction of plugins.
Selenium IDE Plugin
This plugin enables us to call the Selenium IDE’s API. It is used to extend the functionalities of the IDE’s behavior by default. To learn more about plugins, refer to this website.
It is possible to add and create commands with the help of the Selenium IDE’s plugin, find the browser element, and return any responses from the browser.
The Plugin is an integral part of the Selenium IDE.
To learn more about the IDE refer to the main website here.






Selenium WebDriver - Explanation
The Selenium WebDriver is the upgraded version of Selenium 1 or Selenium RC. It utilizes the browser’s support system and environments for seamless integration unlike using API calls. It is as simple as downloading your specific WebDriver and then integrating it into your specific coding language (be it Java, Python, C#, JavaScript, Ruby and so on).
It supports a variety of Operating Systems, such as Linux, Windows OS, MacOS and so on.
There are different types of selenium web drivers to support different browsers. They are:
- Chromedriver: Used for web automation functionalities in Google Chrome. Click here to download.
- EdgeDriver: It is used to automate web browser applications in Microsoft Edge. Click here to download.
- Firefox Driver: Used for performing web automation testing in Mozilla Firefox. It is also known as Geckodriver. Click here to download.
After downloading your Selenium WebDriver, simply mention the directory/path where the WebDriver is downloaded in your code and start working on it.
Example in Python:
Let us understand how to mention the directory/path where the WebDriver is downloaded in Python code:
s = Service( "C:\Program Files\msedgedriver.exe" )
In this way, we learned what the Selenium WebDriver is, and how it is used. Let us now understand the inner workings of the WebDriver Architecture.
Understanding the Selenium Web Driver Architecture
The WebDriver architecture of Selenium consists of 4 components. All 4 components play a major role in how the Web Driver interacts with browsers and extracts data. Let us see the architectural components in detail.
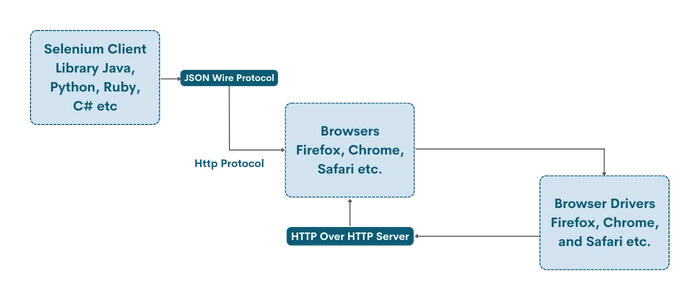
Selenium Client Library
It has various language libraries used to support web/browser automation in different programming languages such as Java, Python, Ruby, Perl, PHP and so on. This makes it so that the Selenium library can be integrated easily into different coding frameworks.
JSON WIRE PROTOCOL Over HTTP Client
Most of the data stored on a website is in JSON format. Primarily used to consume less space on the internet, it is the default format that is returned when a web request is made either by Selenium or other libraries. To transfer data from server to client on the web in JSON format, an HTTP request is used to initiate a client-server connection. This is used to automate sending HTTP requests to the browser to return JSON format replies which can further be formatted using coding techniques.
Browser Drivers
The Browser Drivers of Selenium WebDriver are the ones which initiate a connection between the code and the Browser that is chosen by the user. In order to improve security and prevent the leak of sensitive information, the Browser Drivers are also used to ensure no information about the browser’s working is known to those performing web automation techniques, since it gives room for hackers with malicious intentions to misuse this functionality.
Browsers
The Selenium WebDriver architecture supports various browsers. They are:
- Google Chrome
- Microsoft Edge
- Mozilla Firefox
- Brave
These are some of the Browsers which are compatible with Selenium.
Now that we know the workings of the WebDriver architecture, let us view an example below.
Selenium WebDriver Example
Consider a way in which you need to pull out all the available localities in Chennai, but instead of manually searching and inputting it all into one list, you’d prefer automation since there are more than 100 localities in Chennai, It’d be too time-consuming!
This can be simplified by using the Selenium Library on this Wikipedia page.
Run the code below:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import import
# Open the browser
s = Service( ("C:\Program Files\msedgedriver.exe" )
browser = webdriver.Edge(service=s)
# Open the link
browser.get( "https://en.wikipedia.org/wiki/Areas_of_Chennai" )
# Wait for the page to load fully
time.sleep( 2 )
# Find the element in which the results are in
result = browser.find_element(by=By.XPATH, value= '//*[@id="mw-content-text"]/div[1]/table/tbody' )
string=str(result.text) #Get the text value of the necessary result
string_to_list=string.split(sep= '\n' ) # Convert it into a list
string_to_list.pop( 0 ) # Delete the header
print(string_to_list) # Printing the list
browser.close()
This prints the output:
['Adambakkam', 'Adyar', 'Alandur', 'Alapakkam', 'Alwarpet', 'Alwarthirunagar', 'Ambattur', 'Aminjikarai', 'Anna Nagar', 'Annanur', 'Arumbakkam', 'Ashok Nagar', 'Avadi', 'Ayanavaram', 'Beemannapettai', 'Besant Nagar', 'Basin Bridge', 'Chepauk', 'Chetput', 'Chintadripet', 'Chitlapakkam', 'Choolai', 'Choolaimedu', 'Chrompet','Egmore', 'Ekkaduthangal', 'Eranavur', 'Ennore', 'Foreshore Estate', 'Fort St. George', 'George Town', 'Gopalapuram', 'Government Estate', 'Guindy', 'Guduvancheri', 'IIT Madras', 'Injambakkam', 'ICF', 'Iyyappanthangal', 'Jafferkhanpet', 'Karapakkam', 'Kattivakkam', 'Kattupakkam', 'Kazhipattur', 'K.K. Nagar', 'Keelkattalai', 'Kottivakkam', 'Kilpauk', 'Kodambakkam', 'Kodungaiyur', 'Kolathur', 'Korattur', 'Korukkupet', 'Kottivakkam', 'Kotturpuram', 'Kottur', 'Kovilambakkam', 'Koyambedu', 'Kundrathur', 'Madhavaram', 'Madhavaram Milk Colony', 'Madipakkam', 'Madambakkam', 'Maduravoyal', 'Manali', 'Manali New Town', 'Manapakkam', 'Mandaveli', 'Mangadu', 'Mannady', 'Mathur', 'Medavakkam', 'Meenambakkam', 'MGR Nagar', 'Minjur', 'Mogappair', 'MKB Nagar', 'Mount Road', 'Moolakadai', 'Moulivakkam', 'Mugalivakkam', 'Mudichur', 'Mylapore', 'Nandanam', 'Nanganallur', 'Nanmangalam', 'Neelankarai', 'Nemilichery', 'Nesapakkam', 'Nolambur', 'Noombal', 'Nungambakkam', 'Otteri', 'Padi', 'Pakkam', 'Palavakkam', 'Pallavaram', 'Pallikaranai', 'Pammal', 'Park Town', "Parry's Corner", 'Pattabiram', 'Pattaravakkam', 'Pazhavanthangal', 'Peerkankaranai', 'Perambur', 'Peravallur', 'Perumbakkam', 'Perungalathur', 'Perungudi', 'Pozhichalur', 'Poonamallee', 'Porur', 'Pudupet', 'Pulianthope', 'Purasaiwalkam', 'Puthagaram', 'Puzhal', 'Puzhuthivakkam/ Ullagaram', 'Raj Bhavan', 'Ramavaram', 'Red Hills', 'Royapettah', 'Royapuram', 'Saidapet', 'Saligramam', 'Santhome', 'Sembakkam', 'Selaiyur', 'Shenoy Nagar', 'Sholavaram', 'Sholinganallur', 'Sithalapakkam', 'Sowcarpet', 'St.Thomas Mount', 'Surapet', 'Tambaram', 'Teynampet', 'Tharamani', 'T. Nagar', 'Thirumangalam', 'Thirumullaivoyal', 'Thiruneermalai', 'Thiruninravur', 'Thiruvanmiyur', 'Tiruverkadu', 'Thiruvotriyur', 'Thuraipakkam', 'Tirusulam', 'Tiruvallikeni', 'Tondiarpet', 'United India Colony', 'Vandalur', 'Vadapalani', 'Valasaravakkam', 'Vallalar Nagar', 'Vanagaram', 'Velachery', 'Velappanchavadi', 'Villivakkam', 'Virugambakkam', 'Vyasarpadi', 'Washermanpet', 'West Mambalam']
How it works
By utilizing the Selenium WebDriver module, we download the Edge Driver, which helps us integrate our web automation application into the Browser referred to above, after providing a path to the WebDriver downloaded in your system, you can open the browser with the inbuilt function get() which will open the browser to the Wikipedia page mentioned above.
After going to the website, we need to specify where we need to scrape from the website. This can be done by getting the HTML class/ element dealing with the table. Since the locations are there in a table, we need to get the table element value. This element can be acquired by pressing Ctrl+Shift+I or by right-clicking on the website and selecting “Inspect Element”.
This will open the HTML code running the page. After that, it is as simple as hovering the mouse over the parts of the website till you find the table.
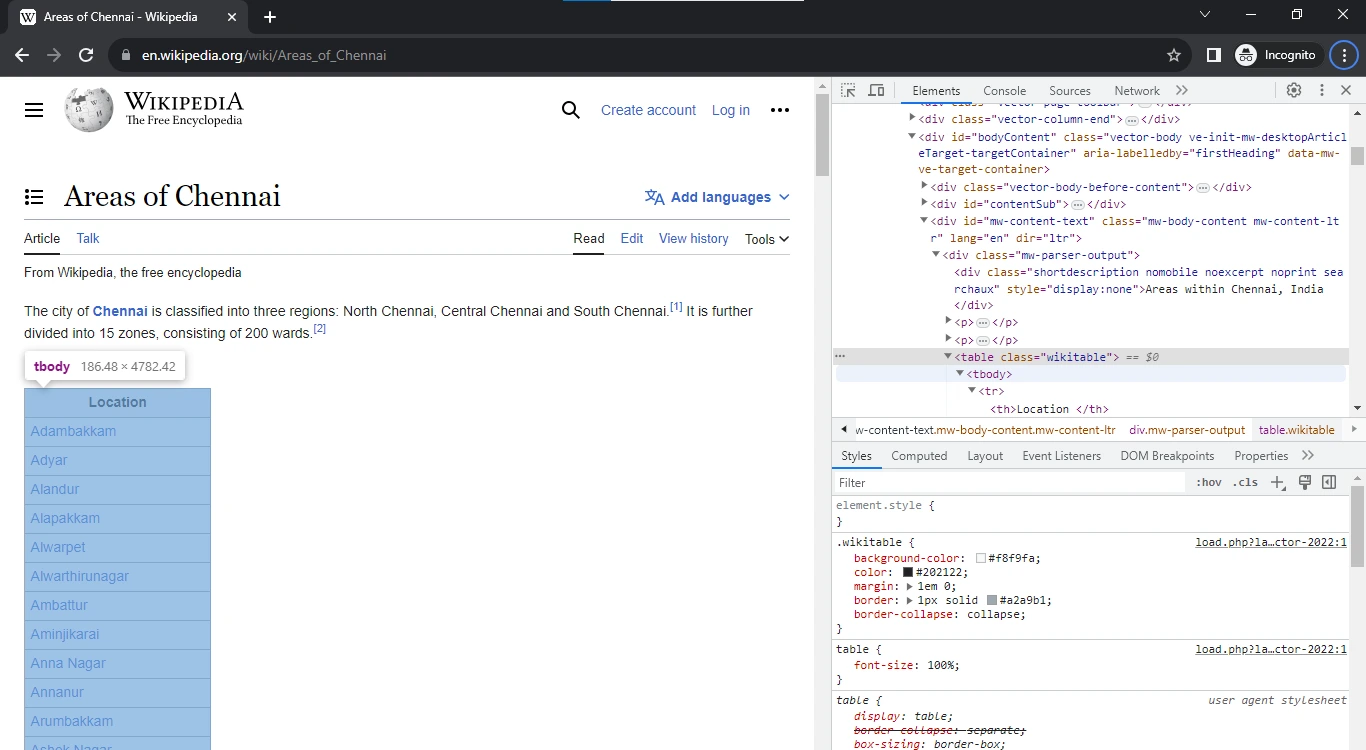
Here, we’ve found the table value. Since it isn’t a main class, we cannot call it directly. A more surefire way to succeed is by copying the XPATH line. By implementing the XPATH value as shown on the website, we can scrape the data in the table and add it to the list. But, as specified earlier, a problem we’ll encounter is that the reply from the server will be in the form of HTML or JSON format.
We then print the text of the results thrown and convert it to string format using Python. After this, we need to sort out another problem. The header of the table will be printed along with the locations and it is part of the whole table. Hence, we need to pop the first value of the list, which can be done using the pop() function in Python. Afterwards, simply print the list you have scraped on the Internet.
In this way, the WebDriver module in Selenium can be used to scrape data from websites.
Conclusion
It is a well-known fact that Selenium WebDriver is one of the most popular web automation libraries. It also has a thriving community that blends well with those who are new to Selenium and would like to learn it. It offers both coding solutions and non-coding solutions, making it extremely appealing to the extreme ends of the spectrum. It provides a mechanism for seamless integration with multiple environments and coding languages too.
One caveat to note is that many websites have codes that actively prevent the scraping of data and shut down the request after a certain limit. This is due to reasons of privacy infringement and stealing sensitive information available on the website for malicious reasons.
Course Schedule
| Name | Date | Details |
|---|---|---|
| Selenium Training |
19 Aug 2023
(Sat-Sun) Weekend Batch |
View Details |
| Selenium with Python Training |
26 Aug 2023
(Sat-Sun) Weekend Batch |
View Details |
| Python Training |
02 Sept 2023
(Sat-Sun) Weekend Batch |
View Details |
Looking For 100% Salary Hike?
Speak to our course Advisor Now !



